As AI agents powered by large language models (LLMs) move from labs to real-world use, a critical tension emerges: the more useful cloud-based memory becomes, the more it exposes sensitive user data. Researchers from MemTensor (Shanghai), HONOR Device, and Tongji University have developed MemPrivacy, a framework that balances privacy and utility. Instead of masking sensitive information or relying on heavy cryptographic methods, MemPrivacy uses a novel technique called local reversible pseudonymization. This allows the cloud to process and store memories without ever seeing actual private values, while the user device seamlessly restores them. Below, we answer key questions about this approach.
What makes cloud memory a privacy risk for AI agents?
When you interact with an AI agent, conversations often include sensitive details like health conditions, email addresses, financial figures, or passwords. In a typical edge-cloud setup, the user's device (edge) handles input, but computation-heavy memory management and reasoning happen in the cloud. This means raw, unfiltered user data travels to and persists in cloud systems. Research shows that multi-turn memory attacks can succeed up to 69% of the time, and leakage attacks against memory systems reach 75% success. Indirect prompt injection can even trick agents into actively eliciting private information. Once sensitive content enters cloud logs, vector databases, or external memory stores, it remains accessible through later stages—well beyond the original interaction. This creates a persistent privacy threat that is far from theoretical.
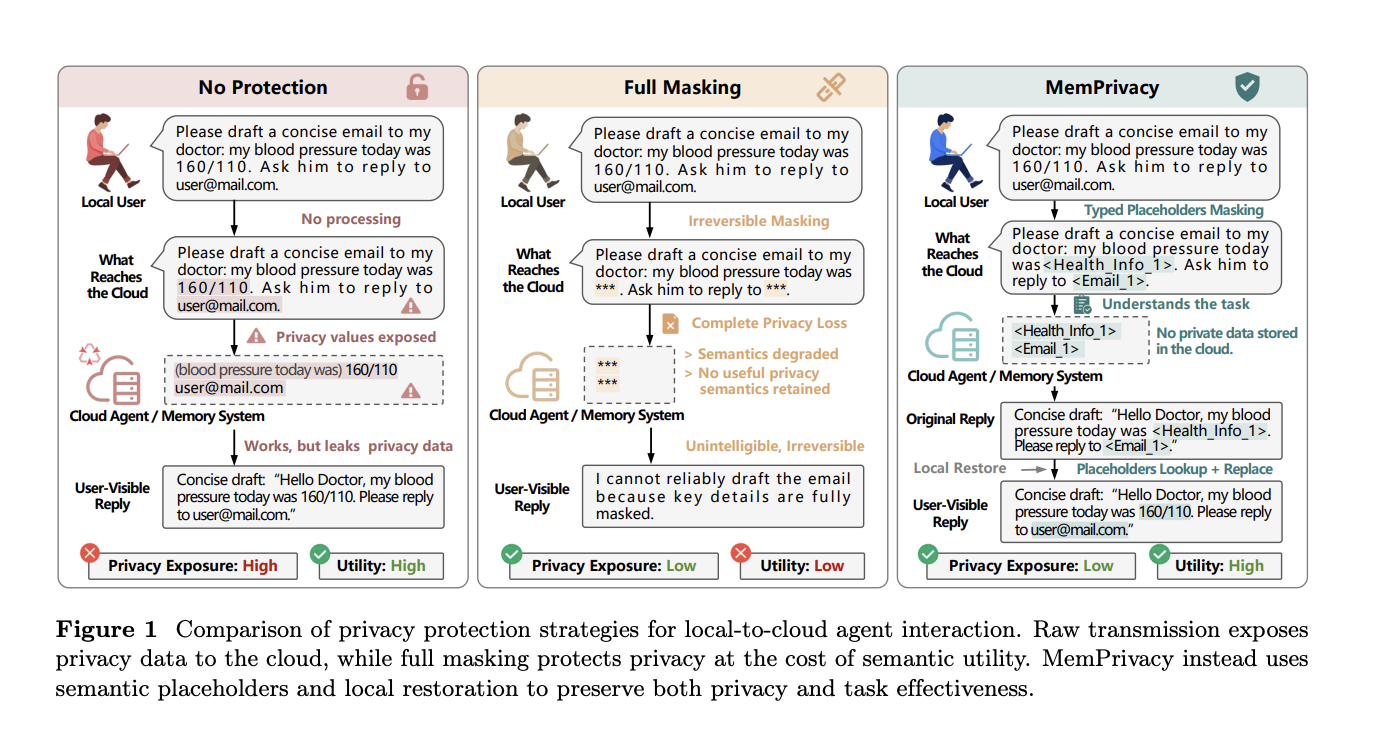
Why haven't previous solutions like masking or differential privacy worked well?
Earlier attempts, such as masking (replacing sensitive values with tokens like ***), destroy semantics. For example, if a user asks an agent to draft a doctor's email and both their blood pressure reading and email address are replaced with ***, the cloud model cannot complete the task meaningfully. Differential privacy and cryptographic protection offer stronger guarantees but are difficult to integrate into interactive memory pipelines without degrading response quality. They add latency, reduce accuracy, or require complex infrastructure that isn't practical for real-time agent interactions. A solution was needed that preserves the utility of cloud memory—enabling reasoning, storage, and retrieval—while preventing exposure of actual private data.
What is local reversible pseudonymization, and how does MemPrivacy use it?
Local reversible pseudonymization is MemPrivacy's core innovation. Rather than masking private content, it replaces sensitive spans with typed placeholders—structured tokens like <Health_Info_1> or <Email_1>—before the input leaves the local device. The cloud model receives semantically intact text and can reason, store memories, and respond normally; it just never sees the actual values. When the cloud returns a response containing placeholders, the local device looks up the originals from a secure local database and substitutes them back in. The user sees a fully coherent, personalized response. This approach is reversible locally: only the user's device holds the mapping, so the cloud never has access to plaintext sensitive data.
What are the three stages of MemPrivacy's pipeline?
MemPrivacy operates in three stages, each designed to protect privacy without sacrificing utility:
- Uplink Desensitization (Stage 1): A lightweight on-device model identifies privacy-sensitive spans in the user's input, classifies each by type (e.g., health info, email) and sensitivity level, and replaces them with typed placeholders. The original-to-placeholder mappings are stored locally in a secure database.
- Cloud Processing (Stage 2): The desensitized input (with placeholders) is sent to the cloud. The LLM-powered agent processes, reasons, and stores memories normally. It can retrieve and combine memories, but only sees the anonymous placeholders.
- Downlink Restoration (Stage 3): When the cloud returns a response containing placeholders, the local device uses the stored mapping to replace each placeholder with the original value. The user receives a coherent, personalized reply, while the cloud never accessed actual private data.
How does MemPrivacy maintain memory utility while protecting privacy?
MemPrivacy preserves utility by keeping the semantic structure intact. Unlike masking (which replaces everything with ***), typed placeholders like <Email_1> convey the type and context of the sensitive data without revealing the actual value. The cloud model can still understand the relationship: it knows that <Email_1> is an email address, and can use it in tasks like drafting a message or verifying an account. The placeholder retains the grammatical role—so the model can reason about it as it would any other word. This means the cloud can store, retrieve, and combine memories effectively, while the local device handles the actual substitution. The result is a system that provides the full benefit of cloud memory with zero exposure of raw sensitive data.
What security risks does MemPrivacy mitigate compared to existing approaches?
MemPrivacy directly addresses several attack vectors that plague conventional cloud memory systems. Multi-turn memory attacks, which can achieve up to 69% success in extracting private information, are neutralized because the cloud never stores actual values. Leakage attacks (75% success rate) fail because the cloud's vector databases and logs contain only placeholders. Indirect prompt injection that tries to trick the agent into revealing user secrets becomes ineffective—the agent can only return placeholders, which are meaningless without the local mapping. Moreover, even if the cloud is compromised, attackers gain only a set of random-looking tokens, not any user data. The local device holds the keys to reversibility in a secure, isolated database. This significantly reduces the attack surface while maintaining full functionality.
Where can I learn more about MemPrivacy and its technical details?
The full paper, titled "Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility", is available on arXiv. You can access it directly at https://arxiv.org/pdf/2605.09530v2. The paper provides in-depth explanations of the three-stage pipeline, the lightweight on-device model used for desensitization, and experiments demonstrating how MemPrivacy achieves strong privacy guarantees with negligible impact on task accuracy. For those interested in practical deployment, the authors also discuss integration with existing edge-cloud architectures and compare their approach against masking, differential privacy, and cryptographic baselines.